Turbo-Compass#
Turbo-Compass Settings#
- --turbo [MIN_SR2]
If you are willing to sacrifice some accuracy in favor of speed, you can run Compass with the
--turboparameter specifying the minimum tolerated Spearman R2 (MIN_SR2) of the output matrix compared to the ground truth Compass matrix. This option is mutually exclusive with--calc-metabolites. By default MIN_SR2=1.0, i.e. no approximation is performed.- --turbo-increments [INC]
Turbo Compass runs by incrementally computing subsets of the reaction score matrix and using these subsets to impute the final reaction score matrix. This argument indicates what percentage is computed in each iteration. Default value is INC=0.01.
- --turbo-min-pct [MIN_PCT]
The minimum tolerated Spearman R2 (SR2) for MIN_PCT of the reactions. Requiring 100% of reactions to meet the SR2 condition is typically too stringent since there always being some reactions that fail to meet this condition. In general, decreasing this argument will cause Compass to run faster but produce more reactions that violate the SR2 condition. The default MIN_PCT=0.99 is enough to fix this artifact without compromising the reconstruction quality.
- --turbo-max-iters [MAX_ITERS]
Maximum number of iterative matrix completion steps. During each iteration, INC percent of the reaction score matrix will be sampled and used to impute the remaining entries of the reaction score matrix. If MIN_PCT of entries achieve a Spearman R2 that is higher than MIN_SR2, then Turbo-Compass will move on to the imputation of the final reaction score matrix without completing all MAX_ITERS iterations.
Recommended Settings#
Different dataset sizes require the use of different Turbo-Compass parameters to strike the right balance between runtime speedup and accuracy. In this section, we provide some rough guidelines on how to choose the best set of parameters.
Scenario 1: dataset contains < 1,000 libraries
For smaller datasets, running vanilla Compass without any speedup is usually the best choice. Although Turbo-Compass does yield significant speedups, the accuracy on small dataset is usually not very high. For completeness, here is a set of recommended parameters if you would still like to speed up your COMPASS run:
--turbo 0.7 --turbo-increments 0.1 --turbo-min-pct 0.99 --turbo-max-iters 1
This set of parameters is chosen based on experiments conducted on the Th17 dataset which contains 290 samples. The runtime and accuracy of various Turbo-Compass parameters are shown here:
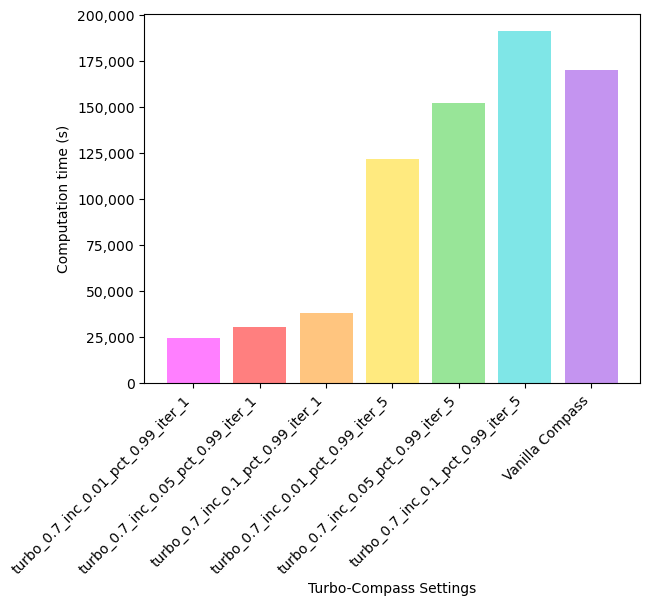
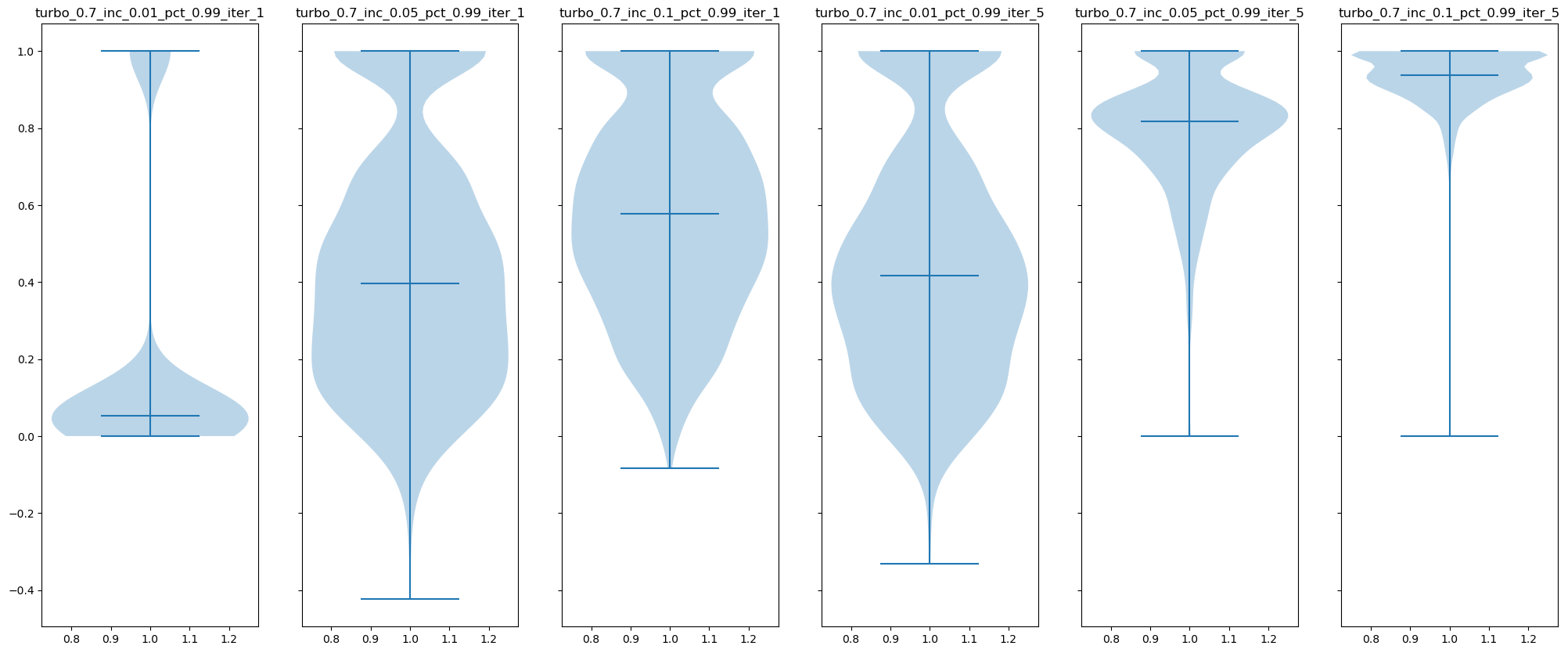
As shown, the runtime of running Turbo-Compass for 5 iterations is comparable to that of running vanilla Compass. Therefore, we suggest that the user simply run 1 iteration of Turbo-Compass along with a relatively large subset of the matrix, e.g. 10% (--turbo-increments 0.1).
Scenario 2: dataset contains 1,000 ~ 10,000 libraries
For medium-size datasets, Turbo-Compass yields significant speedups while still achieving relatively high accuracy. The recommended set of parameters to use is:
--turbo 0.7 --turbo-increments 0.05 --turbo-min-pct 0.99 --turbo-max-iters 1
This set of parameters is chosen based on experiments conducted on the glucose dataset which contains around 5,000 samples. The runtime and accuracy of various Turbo-Compass parameters are shown here:
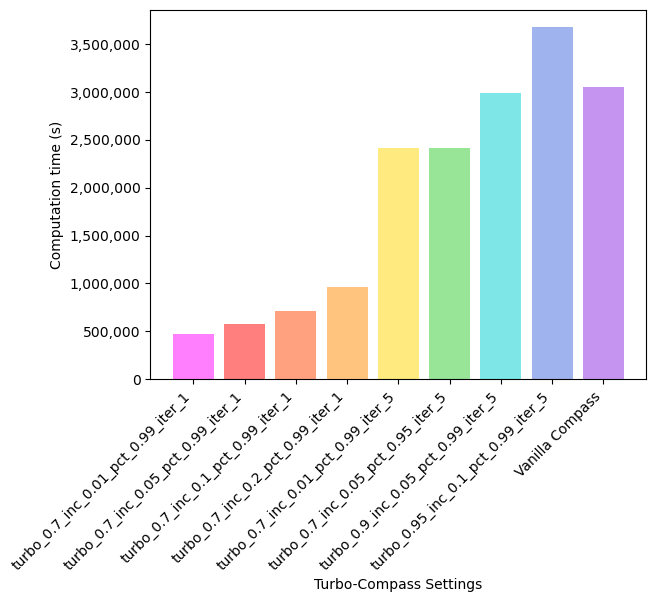
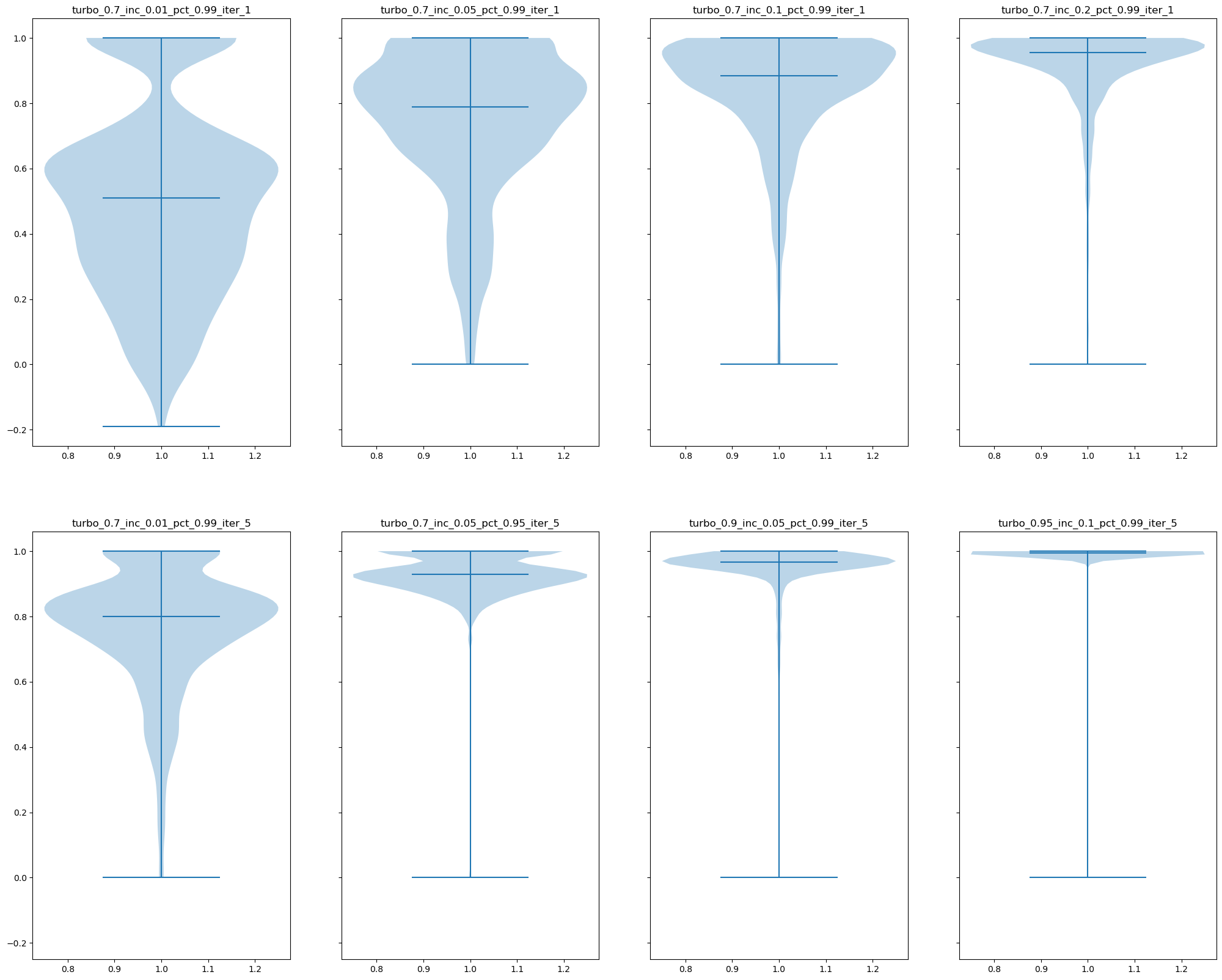
Compared to running on the Th17 dataset, running Turbo-Compass on the glucose dataset yields higher accuracy. We suggest that the user start with running 1 iteration of Turbo-Compass on 5% of the matrix (--turbo-increments 0.05), and if runtime permits, crank up the fraction of entries sampled as well as the number of iterations for better reconstruction quality.
Scenario 3: dataset contains > 10,000 libraries
For large-scale datasets, we suggest that the user perform pseudobulking, i.e. aggregation of the expression values from a group of cells with shared characteristics, such as cells from the same patient, replicate, cell type, etc., on the dataset before proceeding to use Compass. Although this process is highly dependent on the experiments performed to generate the dataset, we provide a tutorial on pseudobulking as reference.
We experimented with some Turbo-Compass parameters for the IBD dataset used in the pseudobulking tutorial. The runtime and accuracy of the various parameters are shown here:
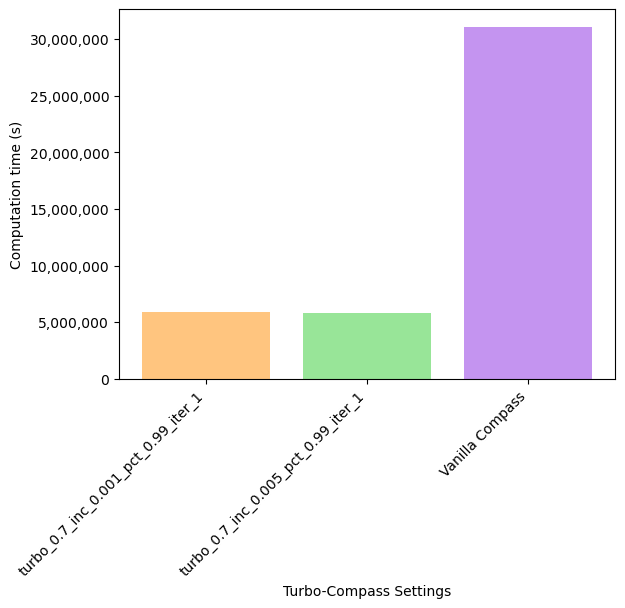
Notice that even though we are only sampling 0.1% of the matrix, the runtime is already around 36 hours when using 50 processors. Although Turbo-Compass still yields significant speedups, the accuracy suffers substantially.
Algorithm#
Turbo-Compass is based on a black-box iterative matrix completion algorithm. In each step of the algorithm, only a subset of entries of the reaction score matrix are computed and used for imputation of the entire reaction score matrix, allowing for faster runtime at the expense of accuracy.
Initially, \(p\) percent of all matrix entries are chosen uniformly at random for computation; \(p\) is a hyperparameter of the method with default value \(p = 0.01\) (corresponding to 1% sampling of the matrix). Next, given the entries observed so far, a model is used to impute the remaining entries. The quality of the imputations is measured by 5-fold cross-validation: 80% of the observed entries are used to fit the model, and the remaining 20% are used to evaluate model fit. This way, we obtain a Spearman correlation for each reaction averaged over the 5 folds. The goal of the algorithm is for every reaction to be imputed with a cross-validated Spearman correlation of \(\rho\), which is a hyperparameter of the method, by default \(\rho = 0.95\) (corresponding to 95%). If all reactions meet this threshold, the algorithm terminates and returns the imputed reaction score matrix (by first re-fitting the model on all the available data, rather than using a specific cross-validation split, which would be wasteful). Otherwise, we query another \(p\) percent of the entries of the matrix, distributing the budget evenly among the reactions failing to meet the threshold. Any remaining budget is evenly distributed among the well-imputed reactions. Cross-validated Spearman correlation is then re-evaluated, and the process is iterated until all reactions meet the cutoff \(\rho\). Thus, if the algorithm performs \(t\) iterations in total, only a fraction \(tp\) of the entries in the reaction score matrix will have been queried. Typically, \(tp\) is much less than 100% (for example 5%), leading to a magnitude order speedup (such as 20x) over naively querying all entries using the vanilla implementation of Compass.
In reality, there might be a handful of reactions that are very hard to predict because they are noisy. To cope with this, we relax the constraint that all reactions must be imputed with a cross-validated Spearman correlation of \(\rho\). Instead, we require that at least \(q\) percent of the reactions meet the threshold; \(q\) is a hyperparameter of the method, by default \(q = 0.99\) (corresponding to 99%).
The last but most important component of the method is the model used to impute entries of the reaction score matrix \(X \in \mathbb{R}^{m \times n}\). We use a low-rank matrix completion model. This means we estimate low-rank matrices \(A \in \mathbb{R}^{m \times k}, B \in \mathbb{R}^{n \times k}\), such that \(X \approx AB^T\). More precisely, we solve:
where \(k\) is the rank of the factorization and \(\lambda \geq 0\) is a regularization hyperparameter; \(P_\Omega\) is the operator that sets the unobserved entries to zero, and \(|| \cdot ||_F\) is the Frobenius norm. We choose \(k = max(1, \lfloor \frac{1}{2}min(n, m)pt \rfloor)\) in the \(t\)-th iteration, which is inspired by the theory of low-rank matrix estimation, and we fix \(λ = 10\) based on manual experimentation. Before fitting the low-rank matrix completion model, we normalize each column (i.e. reaction) of \(X\) to have mean 0 and variance 1; this ensures that all reactions contribute to the loss with similar weight, improving the overall imputation quality.
To solve the optimization problem in Eq. (1) we use the fast alternating least squares (FastALS) method of [1]. Briefly, the algorithm starts from randomly initialized \(A\) and \(B\) and alternates between estimating \(A\) given \(B\) and then \(B\) given \(A\) (coordinate descent). To estimate \(A\) given \(B\) (and vice-versa), the missing entries of \(X\) are first imputed with \(AB^T\) , and then Eq. (1) is solved for \(A\) using the imputed version of \(X\); this is faster than using \(X\) itself because the ridge regression problems involved share the same design matrix. The work [1] shows that the algorithm in fact converges at \(O(1/T)\) rate (where \(T\) is the number of epochs) to a first-order stationary point of Eq. (1), so the algorithm is theoretically sound. The pseudocode for the imputation algorithm is thus as follows:
Algorithm 1: Fast Alternating Least Squares (FastALS)
The computational complexity of each iteration of the algorithm is \(O(kmn)\), for a total of \(O(Tkmn)\). We choose \(T = 100\) epochs during cross-validation, and \(T = 300\) epochs at the very end when we re-fit the model on all the data. Importantly, the algorithm is embarrassingly parallel since it relies on level 3 BLAS operations (matrix-matrix multiplications). Therefore, the cost of fitting the matrix completion model with FastALS is typically insignificant compared to running Compass on all the data.